Vivado implementation tools are really getting close to their ASIC counterparts in terms of capability. The command phys_opt_design now implements useful skew insertion to meet timing. Useful skew is a technique where clock tree is manipulated to have non-zero skew for pipelines which are not completely balanced. Imagine 3 registers, R1, R2, R3 and 2 combinational blocks between them D1 and D2 between R1, R2 and R2, R3 respectively. Now if the delay of D1 block is longer than D2 and this causes timing failures, one has several options to remedy this situation. One can change the RTL and try to balance D1 and D2. This is the least desirable solution as it forces one to run all the regression tests again because RTL is modified. The second solution is to apply register retiming during implementation, ie let the physical optimization tool move some of the logic from D1 to D2 at mapped, maybe even placed gate level. This has a lower cost than RTL changes but it complicates formal verification efforts because now the RTL pipeline does not match gate level pipeline and formal verification needs to understand what retiming has been done. Also one has to verify that no sequential behavior has been changed.
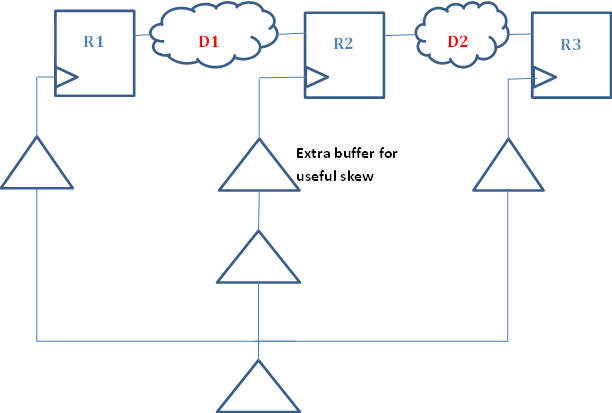
The third and the lowest cost option is to add useful skew to the design. This is accomplished by increasing the time available to D1 block and reducing the time available to D2 block by adjusting the clock tree. Usually clock trees are designed for zero-skew ie all registers in a clock domain see a clock edge as close to each other as possible ie all leaf nodes of a clock tree to each register have the same delay from the root. This facilitates hold timing correctness and flops usually have a output delay larger than hold requirement so with zero-skew even a shift register with no delay between the two registers is guaranteed to have no hold violations with zero-skew. Useful skew changes this design paradigm. In our example because D1 is longer than D2, when it misses timing, there might be positive slack in the D2 path. In this case if we increase the skew to R2 register, this will make more time available to D1 path and less time available to D2 path. If D2 path has enough positive slack, this will allow both paths to meet timing. This method is the least costly as it is implemented in a post-place, post-route design by the tools and it doesn’t need any change in RTL or logic changes after synthesis and keeps the formal verification flow simple.